
1. 텍스트 파일 읽어 화면에 출력하기
2. 텍스트 파일을 액셀 파일로 바꾸기
1) 텍스트 파일을 읽어와 액셀 파일로 변환하기
2) 연산한 데이터를 새 칼럼에 넣기
3) 값을 분석하여 판정한 결과를 새 칼럼에 추가하기
4) 작업한 것을 액셀 파일로 저장하기
1. 텍스트 파일 읽어 화면에 출력하기
Desktop 폴더에 있는 텍스트 파일을 python으로 읽어오고, 읽어온 데이터에서 원하는 데이터만 선택해서 출력해 보자.
1) '텍스트 편집기' 같은 프로그램을 이용해 불러올 텍스트 파일을 만들자.
2) 파일 이름을 'stock_try.txt'로 저장했다.

3) import 명령어로 pandas 모듈을 불러온다. 이후로는 pd로 줄여 부른다.
| import pandas as pd |
4) df = pd.read_csv('텍스트 파일 경로와 이름') 형식으로 텍스트 파일을 읽어와 데이터프레임에 저장할 수 있다.
5) 조금 전에 만들어 둔 stock_try.txt를 읽어와 데이터프레임에 저장하고, df 명령으로 제대로 읽어 왔는지 확인해 보자.
| df = pd.read_csv('/Users/my_open_folder/stock_try.txt') df |
《결과》

6) 텍스트 파일의 첫 번째 열이 칼럼 이름이 되었다.
7) 이번에는 불러온 텍스트 파일에서 '삼성전자'에 대한 것만 출력해 보자.
8) 먼저 Ticker가 삼성전자인 것을 골라 'samsung'이라는 변수를 만들어 저장한다.
df['칼럼 이름'] == '찾으려는 문자' 형식을 사용한다.
| samsung = df['Ticker'] == '삼성전자' |
9) 'samsung'을 print() 문으로 출력하면
| print(samsung) |
《결과》

10) 각 열의 index와 논리값만 출력된다.
11) 데이터 중에서 '삼성전자'인 것만 넣을 데이터프레임을 만들어 저장할 또 다른 변수(여기서는 'prtsamsung')를 만들고, print() 명령으로 출력해야 원하던 결과를 얻을 수 있다.
《결과》

2. 텍스트 파일을 액셀 파일로 바꾸기
텍스트 파일에 나열되어 있는 데이터를 읽어와 액셀 파일로 바꿔 저장한다. 새로운 칼럼을 추가해 보자. 값을 연산하여 새로 만든 칼럼에 입력하거나, 값을 판정하여 새로 만든 칼럼에 결과를 입력해 보자.
1) 텍스트 파일을 읽어와 액셀 파일로 변환하기
- 사용할 텍스트 파일을 만든다.
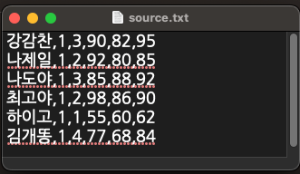
- 만들어진 텍스트 파일을 읽어와 데이터프레임에 저장하고, df 명령으로 확인한다.
- 쉼표(,)로 구분된 데이터는 그냥 파일 경로와 이름만 적어 불러올 수 있다.
- 다른 문자나 tab으로 구분되어 있는 텍스트 파일은 delimiter를 추가해야 한다.
- 예를 들어 tab으로 구분된 파일이면 delimiter = "\t"를 추가한다.
| import pandas as pd df = pd.read_csv('source.txt') df |
《결과》

- 칼럼 이름을 지정하지 않아 텍스트 파일의 첫 줄 데이터가 칼럼 이릉으로 지정되었다.
- 칼럼 이름은 작은따옴표(') 속에 쉼표(,)로 구분하여 차례로 지정할 수 있다.
- 칼럼 이름을 만들며 텍스트 파일을 읽어 오고, df 명령어로 확인
| df = pd.read_csv('source.txt', header = None, names=['name', 'year', 'class', 'kor', 'eng', 'math']) |
《결과》
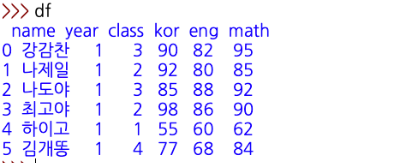
- 칼럼 이름이 만들어졌다.
2) 연산한 데이터를 새 칼럼에 넣기
- 오른쪽 끝에 'total'이란 칼럼을 추가한다.
- kor, eng, math 합계 점수를 계산하여 'total' 칼럼에 입력되게 하자.
| df['total'] = df['kor'] + df['eng'] + df['math'] |
- 평균값을 넣을 'avg' 칼럼을 만들고, 'total' 칼럼의 값을 이용해 평균을 계산하여 값이 입력되게 하자.
| df['avg'] = df['total'] /3 |
- df 명령으로 결과 확인
《결과》
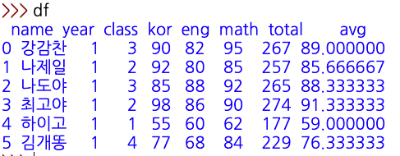
- 오른쪽 끝에 'total', 'avg' 칼럼이 추가되고 계산 결과가 입력되었다.
3) 값을 분석하여 판정한 결과를 새 칼럼에 추가하기
평균(avg) 점수가 90 이상이면 'A', 80~90 이하면 'B', 70~80 이하면 'C', 아니면 'D'로 판정하여
'grades'라는 리스트를 만들고, 'grade'라는 칼럼을 추가로 만들어 판정 결과가 입력되게 하자.
| grades = [] # 'grades' 리스트 정의 for row in df['avg']: # 'avg' 값 판정 if row >= 90: grades.append('A') elif row >= 80: grades.append('B') elif row >= 70: grades.append('C') else: grades.append('D') df['grade'] = grades # 'grade' 칼럼을 만들고 'grades' 리스트 데이터 입력 |
- df 명령어로 확인하면
《결과》
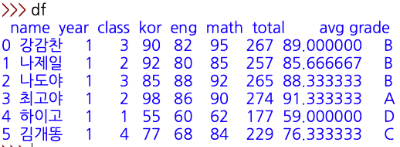
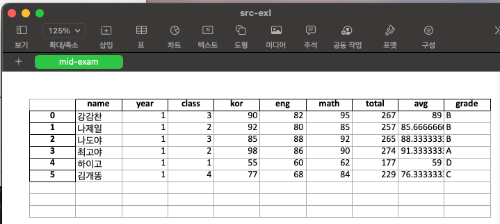
4) 작업한 것을 액셀 파일로 저장하기
지금까지 작업한 내용이 모두 들어가 있는 것을 액셀파일(src-exl.xlsx)의 시트(mid-exam)로 만들어 저장하자.
df.to_excel('파일이름.xlsx', sheet_name = '시트이름') 형식을 사용하면 된다.
| df.to_excel('src-exl.xlsx', sheet_name = 'mid-exam') |
《결과》 Numbers로 열어 본 액셀 파일
'Manuals > 파이썬' 카테고리의 다른 글
| 파이썬 turtle, 함수 사용 꽃 그리기 (1) | 2023.03.22 |
|---|---|
| 파이썬 tkinter, 냉동식품 관리(1) (0) | 2023.03.11 |
| 파이썬 turtle, 도형을 이용한 꽃 그리기 (0) | 2023.02.23 |
| 파이썬 pandas, 암기 프로그램(무작위 출제/채점) (0) | 2023.02.12 |
| 파이썬, matplotlib을 이용한 선 그래프 그리기 (0) | 2023.02.04 |